
Transformer modeller har siden sin introduktion i 2017 været en populær deep learning model. Dens brug af self-attention har vist sig at være særdeles effektiv, først inden for natural language processing (NLP) og senere computer vision. Transformer frameworket var oprindelig introduceret på sekvenser af ord. Her var håbet at modellen skulle lære, at forstå den semantiske mening af en sætning og ikke blot hvert ord for sig. Tag sætningen:
“Manden spiser en stor is”
For at forstå hvad sætningen præcis betyder er man nødt til, at forstå hvilke ord der har størst betydning for hvert ord. Så fx at ordet “stor” henvender sig til “is” i stedet for “Manden”. Dette kan naturligt overføres til videoer der er sekvenser af billeder. Her kan man også forestille sig at nogle frames har større betydning for den semantiske betydning af en video end andre. Da transformer modellen “attender” alle sekvenser og den her attention-mekanisme ikke nødvendigvis fungerer i rækkefølge, kan processen paralleliseres mere end fx Recurrent Neural Networks. Dette kan reducere træningstiden og give mulighed for at træne på større netværker.
Men kan transformer frameworket fungere til at klassificere et enkelt billede? Dette blev forsøgt af Dosovitskiy et al. 2021, der opnåede resultater der var sammenlignelige med state-of-art Convolutional Neural netværker (CNN) med Vision Transformer (ViT). Det er netop dette netværk jeg har implementeret i Tensorflow på CIFAR-10 datasættet, der består af 60000 billeder fordelt ud på 10 klasser:
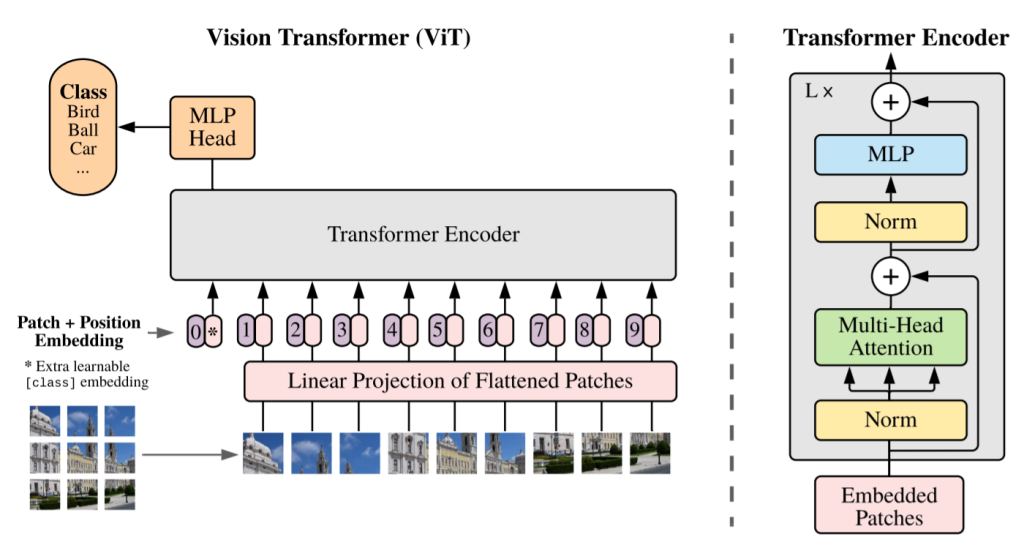
Jeg startede med at loade billederne ned og dele dem op i mindre bokse. Derved blev hvert billede lavet om til en sekvens af mindre billeder, der nu kunne indsættes i ovenstående transformer model. Dette blev gjort ved at benytte tensorflow.image.extract_patches(). Da min datapipeline stod klar kunne jeg begynde at lave de Classes der udgør hele modellen som patch og positions embeddings, MLP lagene samt multi-head attention. Hvoraf sidst nævnte blev bygget med tensorflow.keras.layers.MultiHeadAttention(). Endelig kunne jeg sammensætte min model:
class ViT(Model):
def __init__(self, batch_size, num_patches, patch_size, num_transformer_layers, > num_heads_of_MSA, proj_dimension, MLP_proj_dimension):
super(ViT, self).__init__()
self.num_transformer_layers = num_transformer_layers
self.num_heads_of_MSA = num_heads_of_MSA
self.patch_size = patch_size
self.make_patches = make_patches(batch_size, patch_size)
self.patches_encoder = patches_encoder(num_patches, proj_dimension)
self.layer_norm = []
self.MSA = []
self.MLP = []
for i in range(num_transformer_layers):
self.layer_norm.append(LayerNormalization(epsilon=1e-6))
self.layer_norm.append(LayerNormalization(epsilon=1e-6))
self.MLP.append(MLP(dimensions=[MLP_proj_dimension, proj_dimension]))
self.MSA.append(MSA(num_heads_of_MSA, proj_dimension))
self.layer_norm.append(LayerNormalization(epsilon=1e-6))
self.MLP.append(MLP(dimensions=[MLP_proj_dimension*2, MLP_proj_dimension]))
self.final_layer = Dense(num_classes)
def call(self, x, training=None):
x = self.make_patches(x)
x = self.patches_encoder(x)
CLS = tf.repeat(tf.zeros((1,1,proj_dimension)), tf.shape(x)[0], axis=0)
x = tf.concat([CLS, x], axis=1)
for i in range(self.num_transformer_layers):
skip= x
x=self.layer_norm[i*2](x)
x=self.MSA[i](x)
x=tf.keras.layers.Add()([x,skip])
skip2=x
x=self.layer_norm[(i*2)+1](x)
x=self.MLP[i](x)
x=tf.keras.layers.Add()([x,skip2])
x=x[:,0,:]
x=self.layer_norm[self.num_transformer_layers*2](x)
x=self.MLP[num_transformer_layers](x)
output_logits = self.final_layer(x)
return output_logitsHerefter kunne jeg påbegynde min træning. Mit netværk bestod af 8 transformer lag og 8 multihead self attention hoveder. Jeg trænede 10 epoker på 40000 billeder, af størrelse 32×32 der alle var delt op i bokse af 4×4. Jeg benyttede en Adam optimizer og en batch size på 64.
Resultater
Min model opnåede en test accuracy på cirka 60% med en top 5 accuracy på 95%. Dette er fine resultater, men selvfølgelig ikke godt nok til at være sammenlignelig med state-of-art CNN.
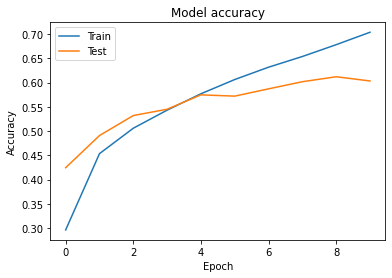


Så hvorfor lykkedes jeg ikke med at slå state-of-art CNN’er med min Vision Transformer? Det skyldes ganske enkelt at jeg ikke har benyttet mig af transfer learning i denne implementering, som det kræver før ViT virkelig er anvendelig på mellemstore dataset som CIFAR-10. Vi har nemlig at ViT kun slår de bedste CNN’er, når de trænes på virkelig store datasæt. Sammenlignet med CNN’er antager man ikke at nærliggende pixels har stor sandsynlighed for at være tæt beslægtede eller at objekter kan variere i størrelse og positioner på billeder. Det skal ViT selv lære, hvilket kræver en masse pretraining. Men når den gør dette har ViT’er potentialet til også at fange nogle tilfælde, hvor pixels, der ikke er i nærheden, har en indflydelse på den semantiske betydning af billedet. Derved kan ViT også udkonkurrere CNN’er når den er trænet rigtigt.
For at opsummere, har jeg implementeret en Vision Transformer model i tensorflow i python. Derudover har jeg fået illustreret hvorfor pretraining på et stort dataset er essentielt for ViT. Denne fulde implementering er tilgængelig på mit GitHub.